Available Number of Questions: Maximum of
65 Questions
Exam Name: SnowPro Advanced: Data Engineer Certification Exam
Related Certification(s):
Snowflake SnowPro Certification, Snowflake SnowPro Advanced Certifications
Snowflake DEA-C01 Exam Topics - You’ll Be Tested in Actual Exam
The Snowflake DEA-C01 exam assesses your knowledge and skills in managing data within the Snowflake Data Cloud. It covers a range of critical topics, including data security and compliance, data sharing and governance, and the efficient use of Snowflake's platform for data warehousing and analytics. You'll delve into best practices for data loading and transformation, as well as explore the various options for data storage and access control. The exam also emphasizes the importance of performance tuning and optimization techniques to ensure your data warehouse runs smoothly and efficiently. Additionally, you'll learn about the various tools and features within Snowflake's platform, such as Snowpark, which allows you to build custom applications and extend the platform's capabilities. Understanding the different types of users and their roles, along with the concept of virtual warehouses, is crucial for effective data management. Finally, you'll gain insights into troubleshooting common issues and leveraging the platform's documentation and support resources.
Snowflake DEA-C01 Exam Short Quiz
Attempt this Snowflake DEA-C01 exam quiz to self-assess your preparation for the actual Snowflake SnowPro Advanced: Data Engineer Certification Exam . CertBoosters also provides premium Snowflake DEA-C01 exam questions to pass the Snowflake SnowPro Advanced: Data Engineer Certification Exam in the shortest possible time. Be sure to try our free practice exam software for the Snowflake DEA-C01 exam.
1of 0 questions |
Snowflake DEA-C01 Exam Quiz
✓ 0 answered
🔖 0 bookmarked
SnowflakeDEA-C01
Q1:
A company is building a dashboard for thousands of Analysts. The dashboard presents the results of a few summary queries on tables that are regularly updated. The query conditions vary by tope according to what data each Analyst needs Responsiveness of the dashboard queries is a top priority, and the data cache should be preserved.
How should the Data Engineer configure the compute resources to support this dashboard?
○
AAssign queries to a multi-cluster virtual warehouse with economy auto-scaling Allow the system to automatically start and stop clusters according to demand.
○
BAssign all queries to a multi-cluster virtual warehouse set to maximized mode Monitor to determine the smallest suitable number of clusters.
○
CCreate a virtual warehouse for every 250 Analysts Monitor to determine how many of these virtual warehouses are being utilized at capacity.
○
DCreate a size XL virtual warehouse to support all the dashboard queries Monitor query runtimes to determine whether the virtual warehouse should be resized.
SnowflakeDEA-C01
Q2:
Which callback function is required within a JavaScript User-Defined Function (UDF) for it to execute successfully?
○
Ainitialize ()
○
BprocessRow ()
○
Chandler
○
Dfinalize ()
SnowflakeDEA-C01
Q3:
A Data Engineer enables a result cache at the session level with the following command:
ALTER SESSION SET USE CACHED RESULT = TRUE;
The Engineer then runs the following select query twice without delay:
The underlying table does not change between executions
What are the results of both runs?
○
AThe first and second run returned the same results because sample is deterministic
○
BThe first and second run returned the same results, because the specific SEED value was provided.
○
CThe first and second run returned different results because the query is evaluated each time it is run.
○
DThe first and second run returned different results because the query uses * instead of an explicit column list
SnowflakeDEA-C01
Q4:
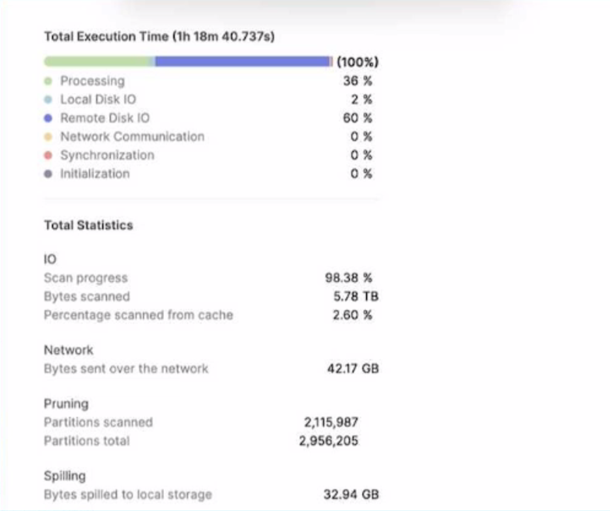
A large table with 200 columns contains two years of historical dat
a. When queried. the table is filtered on a single day Below is the Query Profile:
Using a size 2XL virtual warehouse, this query look over an hour to complete
What will improve the query performance the MOST?
○
Aincrease the size of the virtual warehouse.
○
BIncrease the number of clusters in the virtual warehouse
○
CImplement the search optimization service on the table
○
DAdd a date column as a cluster key on the table
SnowflakeDEA-C01
Q5:
A table is loaded using Snowpipe and truncated afterwards Later, a Data Engineer finds that the table needs to be reloaded but the metadata of the pipe will not allow the same files to be loaded again.
How can this issue be solved using the LEAST amount of operational overhead?
○
AWait until the metadata expires and then reload the file using Snowpipe
○
BModify the file by adding a blank row to the bottom and re-stage the file
○
CSet the FORCE=TRUE option in the Snowpipe COPY INTO command
○
DRecreate the pipe by using the create or replace pipe command